
On the 2nd on June 2022 an online meeting was held with the participation of consortium members and Gerzson Boros AI expert to arrive to a common understanding about the exact process of the online monitoring and clarify questions.
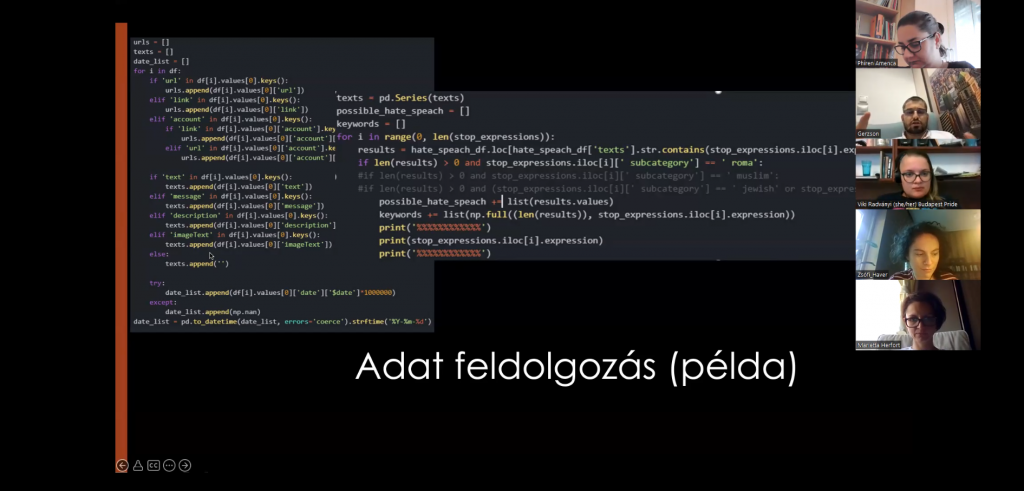
The meeting started with a round of introductions after which Gerzson Boros explained how exactly the algorithm and the monitoring process works: from previous experience and projects, there is already a list of expressions which indicates hate speech or hurtful speech in a text (article, post, or comment), and the list was extended with additional expressions by the partners in the previous weeks. It contains hateful, stereotypical words which are usually used for Roma, Jewish, LGBTIQ, Muslim and migrant people in a discriminatory, degrading manner, as well as “code words” used instead of direct slurs (for example, Roma are often referred to as “Swedish” in derogatory texts, so this word was also added to the list). These will be words the algorithm searches for, and if they appear in a text online, it will be added to an excel table for the volunteers to check.
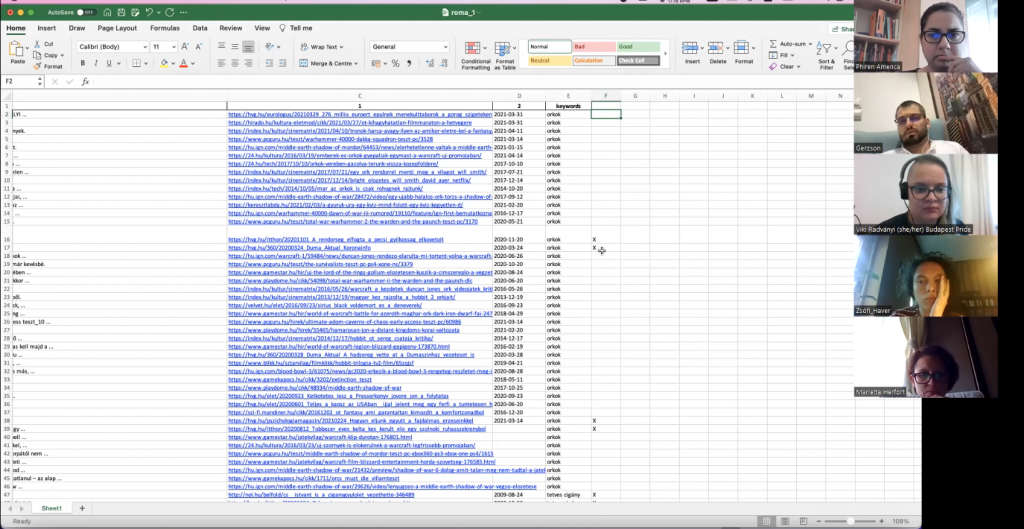
The program will be run on approximately 70 websites, social media profiles and pages, which are known to contain hate speech or hurtful speech. This list was compiled by the partnering organization based on their experience and available research. Once the software is set up, it will start scraping the given platforms and collect all the relevant comments and texts, which will be rendered into a table together with the links to the texts, so annotators can check their context and judge whether they constitute hate speech or hurtful speech. It is necessary, because jokes, art and ironic texts may also be collected by the program. By identifying hate speech, the annotators constantly teach the algorithm to make better choices in the future, so the artificial intelligence will become better and better at finding the relevant content with time.
As now, we do not have information about the number of texts the program will scrape, the team agreed that in the beginning 8-10 volunteers will be recruited for the annotation task, and in the near future (in 2-3 weeks) this number will be evaluated and if needed, additional volunteers will be involved. All volunteers are getting an in-depth training during the summer about the meaning, legal background, characteristics of hate speech, so they can start working in an informed manner.
The consortium agreed on continuing moderating their social media platforms against hate speech, as the algorithm will be able to scrape the data between the appearance of such hurtful texts and their deletion by the admins.
With this thorough understanding, the team could agree on a first training for the second half of June, where themselves and the interested volunteers of the organizations will gain important knowledge about hate speech in general, and its specificities relevant to our communities.

he „CHAD – Countering Hate Speech and Hurtful Speech against Diversity: Roma, LGBTIQ, Jewish and Migrant Communities” project (project nr. 101049309) is funded by the Citizens, Equality, Rights and Values Programme (CERV) of the DG Justice, European Commission and coordinated by RGDTS Nonprofit Llc. in partnership with Haver Informal Educational Foundation, Rainbow Mission Foundation and Political Capital. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the Citizens, Equality, Rights and Values Programme. Neither the European Union nor the granting authority can be held responsible for them.